Tool
- 네이버 OCR General 버전
- python BeautifulSoup, Selenium
- Spring boot 2.7.7
- AWS Lambda, API Gateway
- Docker
OCR로 영수증에서 텍스트 추출하기
Naver에서는 영수증에 특화된 OCR을 제공하지만 너무 비싸서 General 버전의 OCR을 이용해서 텍스트를 추출했습니다.
상품 이름 외의 데이터는 정규식을 이용하거나 특정 문자를 필터링해서 List형태로 추출해냈습니다.
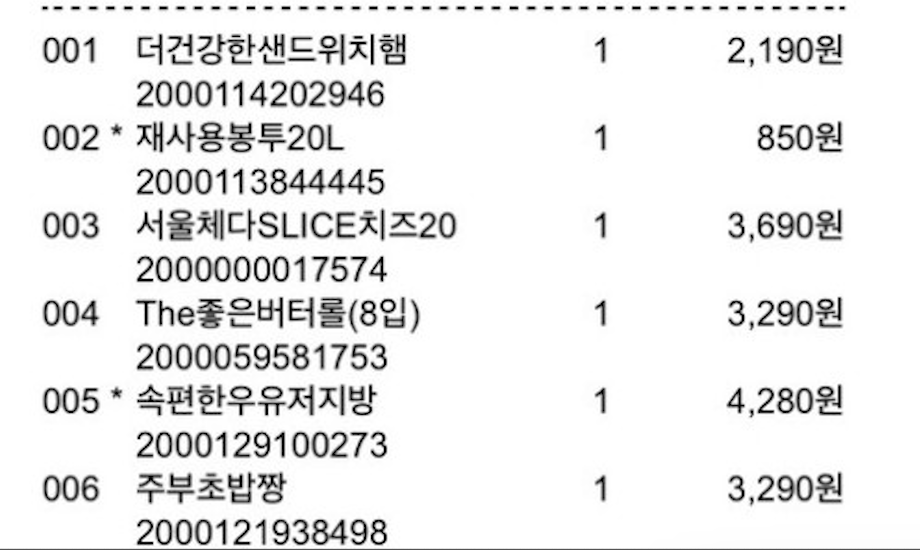
)

분류 모델 만들기
분류모델을 만들기 위해서는 dataset이 필요해서 사용자들이 자주 사용할 마트를 선정해서 크롤링을 통해 데이터를 15000개 수집했습니다.
- 전국통합식품영양성분표준데이터에 있는 식품 데이터를 사용했습니다.
- 모델은 scikit-learn의 CountVectorizer 모델을 사용했습니다.
문제상황
학습 시킨 모델이 정확도가 너무 높게 나오는 과적합 문제 발생
- 문제 발생한 이유 예상 : 크롤링한 데이터 15000개 공공데이터에서 가져온 식품데이터 35000개가 있는데 식품 데이터가 식품이 아닌 데이터보다 너무 많습니다.
- 텍스트 데이터를 학습시키는데 수집한 데이터의 이름이 단어 하나가 아닌 '풀무원 [풀무원 Pulmuone] 국산 콩 찌개용 투컵 두부 320g' 이런식으로 되어 있어서 feature의 수가 굉장히 많아지다 보니 훈련 데이터에만 맞춰져 과적합됐을 확률
2번은 데이터를 전처리를 해야해서 오래걸릴 것 같아서 1번 문제를 해결해 보려고 했습니다.
시도한 방법
- label 0은 식품이 아닌 데이터 label 1은 식품 데이터인데 label 0에 label 1보다 높은 가중치를 적용했습니다.
- 시그모이드 함수로 확률을 얻는데 0.5 이상이면 label 1로 분류하던 데이터를 0.7이상으로 변경했습니다.
- 학습률을 낮추고 배치 사이즈를 늘렸습니다.
- Layer 늘리기, 데이터 전처리, 오버 샘플링
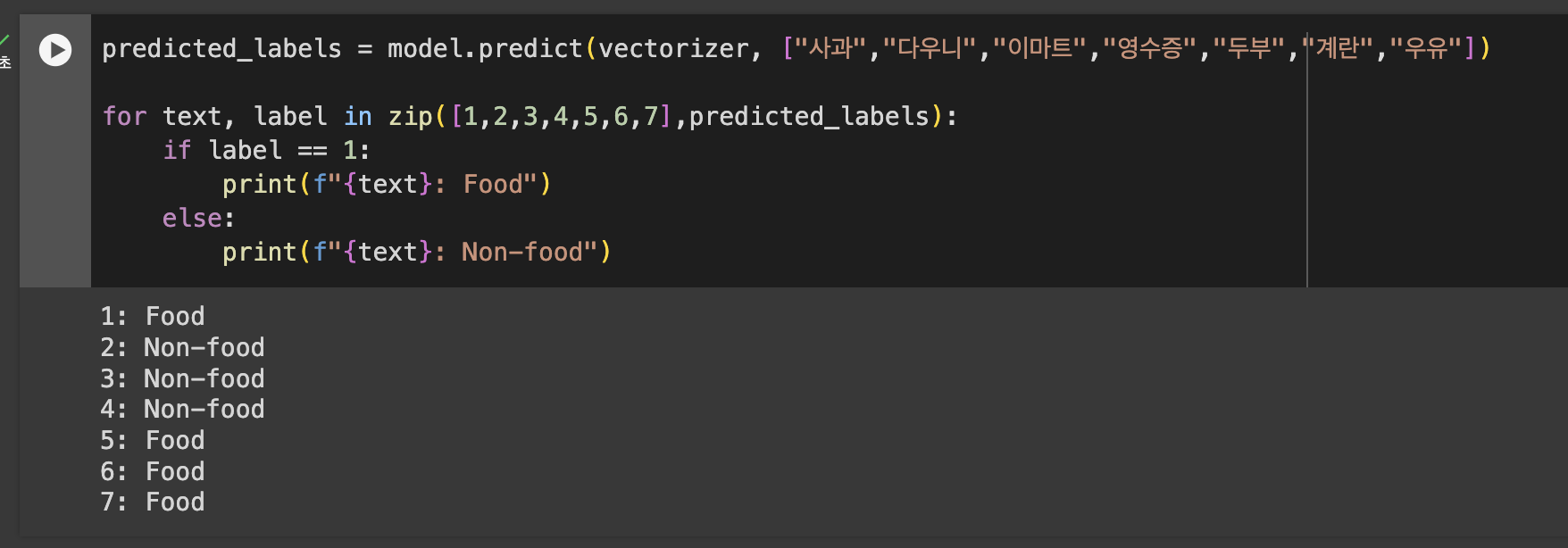
모델 테스트
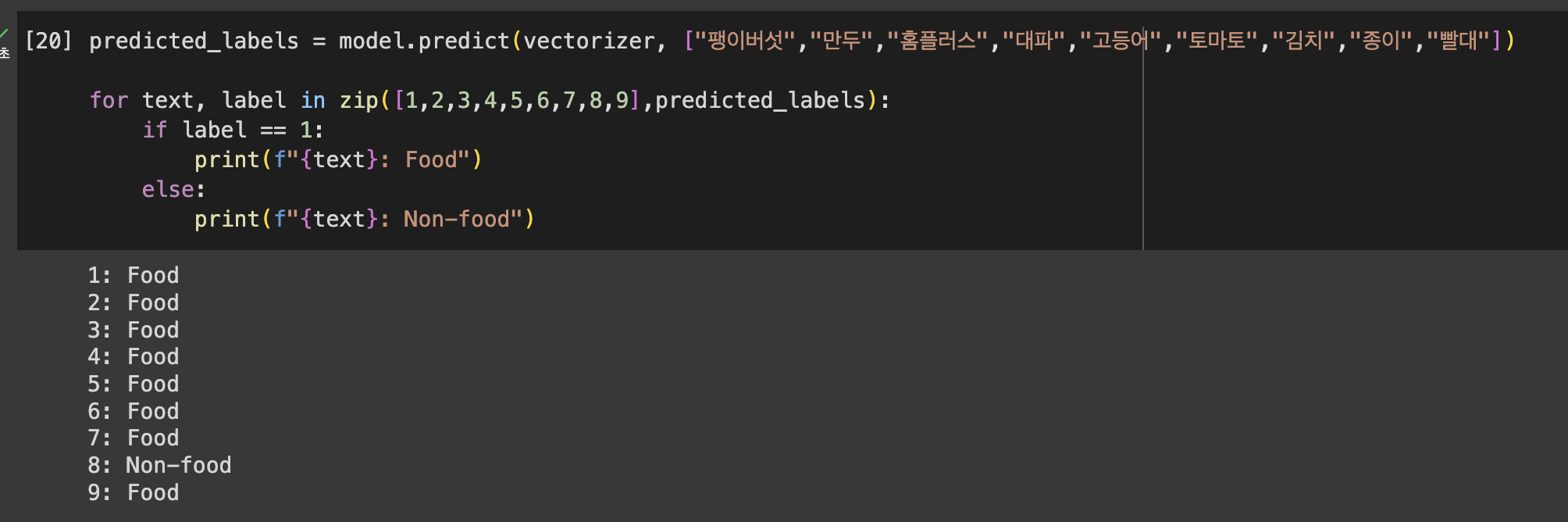
몇몇 데이터는 잘못 분류 되는 것을 확인할 수 있었습니다.
모델을 훈련시키고 joblib을 이용해서 저장하고 docker 이미지로 만들어서 aws lambda를 통해서 배포했습니다.
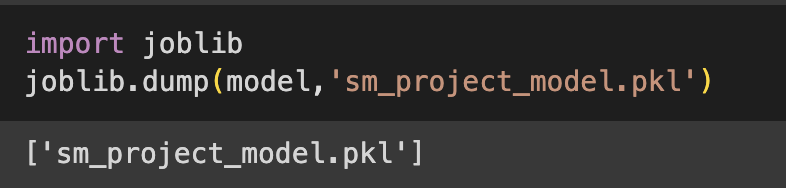
최종 훈련 모델
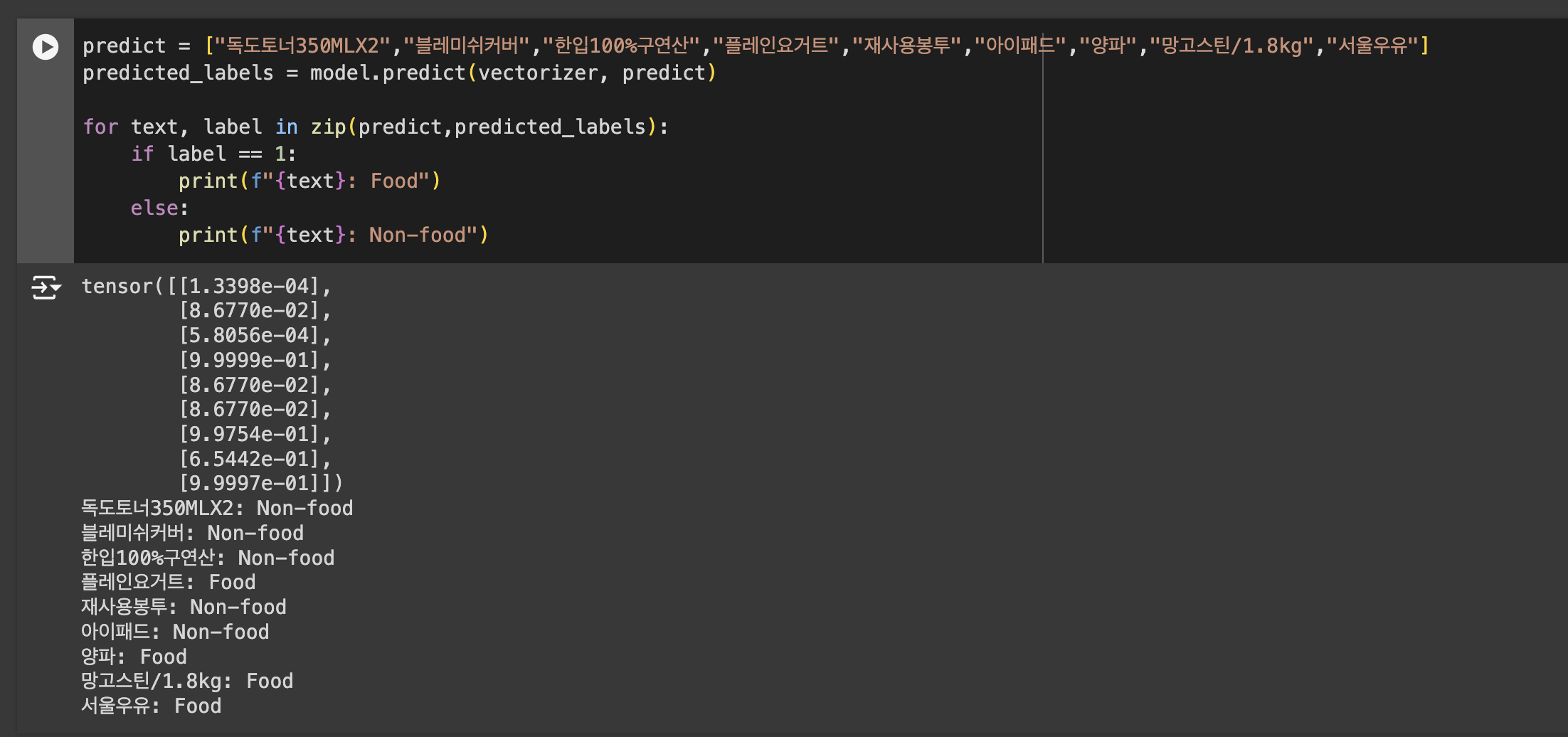
정확도는 0.7로 데이터 탓으로 타협했습니다.
(데이터 전처리를 하기엔 시간이 너무 오래 걸릴 것 같았습니다.)
람다에 이미지를 올리기 위해서 먼저 ECR에 이미지를 만들어서 올렸습니다.
- ECR Repo 생성하기
- aws cli를 통해서 ecr에 이미지를 올리기 위해서 사용자를 생성해서 key를 이용해서 접근한다.
- docker 이미지를 만들기 위한 파일 작성
RUN pip install --upgrade pip
COPY requirements.txt ${LAMBDA_TASK_ROOT}
RUN pip install -r requirements.txt
COPY *.py ${LAMBDA_TASK_ROOT}
COPY *.pickle ${LAMBDA_TASK_ROOT}
CMD [ "lambda_function.lambda_handler" ]
- ***aws cli를 이용해서 ecr에 이미지 올리기***
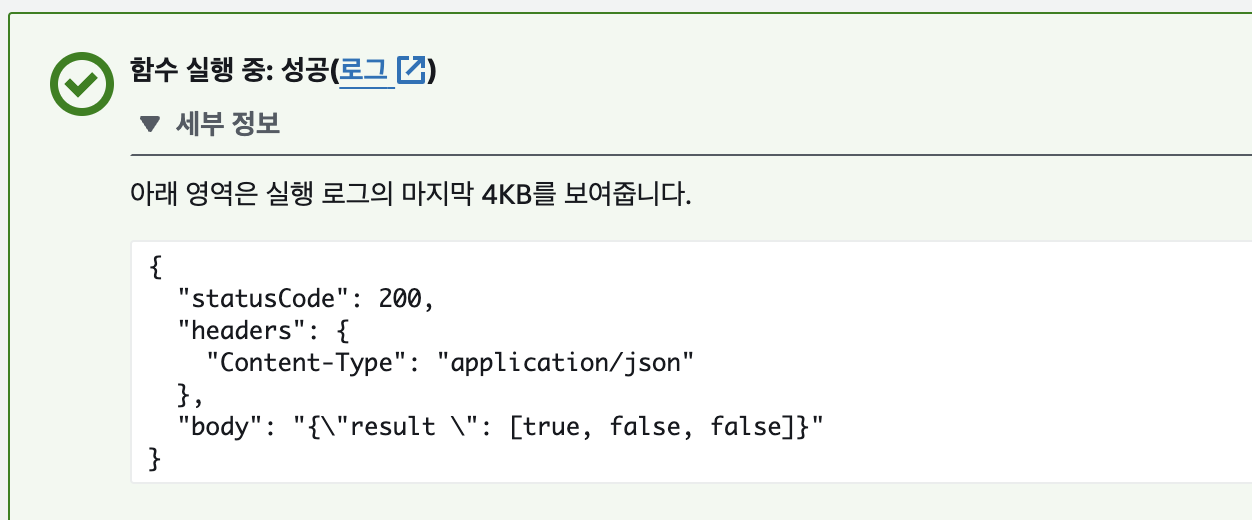
 - ***이미지를 이용해서 lambda 실행시키기***
){kind=link}
](https://velog.velcdn.com/images/khj372/post/ac02bd62-dc1a-459b-97a6-efa68e4ec4b1/image.png)!%5B%5D(https://velog.velcdn.com/images/khj372/post/7959a046-6dc5-43ef-bc35-27d9083c42ff/image.png)){kind=link}
- Spring boot 서버에서 lambda함수 사용할 수 있도록 api gateway 추가하기
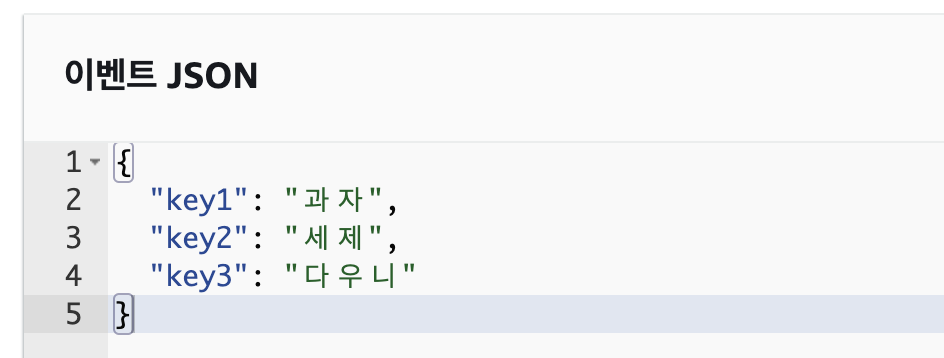
- Spring boot 서버에서 테스트
FeignClient를 이용해서 요청을 보냈습니다
//LambdaFeignClient
@Component
@FeignClient(name = "LambdaFeignClient", url = "${cloud.aws.lambda.url}", configuration = LambdaFeignConfiguration.class)
public interface LambdaFeignClient {
@PostMapping("/default")
LambdaResponse getFood(@RequestBody LambdaRequest foodRequest);
}
//요청 후 응답 처리 로직
public List<String> classifyFood(List<String> foodList) throws Exception{
//구현한 모델을 lambda 함수를 이용해서 만든 api를 호출합니다.
//request로는 영수증에서 추출하고 1차적으로 필터링한 상품들
LambdaResponse classifyFoodList = lambdaFeignClient.getFood(LambdaRequest.builder()
.food(foodList)
.build());
String s = classifyFoodList.getBody();
//결과가 "{\"result \": [true, true, true, true, true, true]}"} 이런식으로 넘어 오는데 boolean 값만 뽑아오기 위함
String resultString = s.substring(s.indexOf('[') + 1, s.indexOf(']'));
String[] result = resultString.split(", ");
//식품인지 아닌지 filtering된 상품들만 배열에 담습니다.
List<String> newFoodList = new ArrayList<>();
for (int i = 0; i < foodList.size(); i++){
if(result[i].equals("true")){
newFoodList.add(foodList.get(i));
}
}
return newFoodList;
}Trouble shooting
문제상황 : 이미지를 ecr에 올리고 lambda를 실행시켜 봤지만 app 모듈을 찾을수 없다고 뜬다..
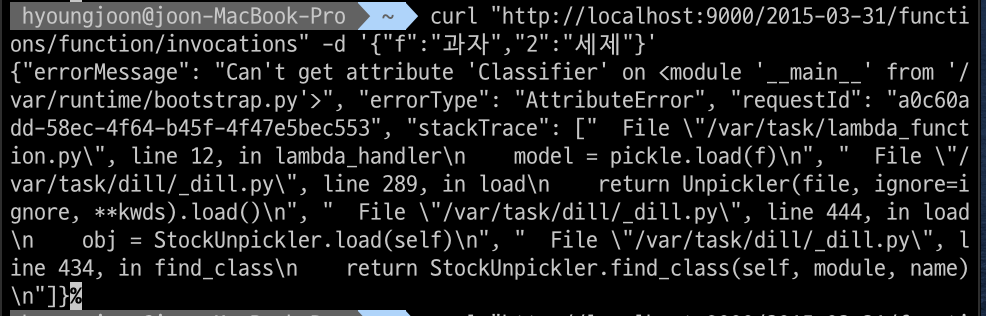
해결: pickle 모듈로 모델을 저장한 것을 dill을 사용해서 모델을 저장했더니 인되었습니다.(마지막에 수정한게 모듈이지만 중간중간 코드도 수정해보고 버전도 수정해보고 Classifier클래스도 lambda_function.py에 선언도 해보고 많은 과정이 있었습니다..)
문제 상황: 이번엔 토치 모듈을 못 찾는다고 나왔습니다.. lambda function과 분리시킨 classifier.py에서 torch를 사용하는데 classifier.py 파일에도 import torch를 했지만 인식을 못하는 상황입니다..
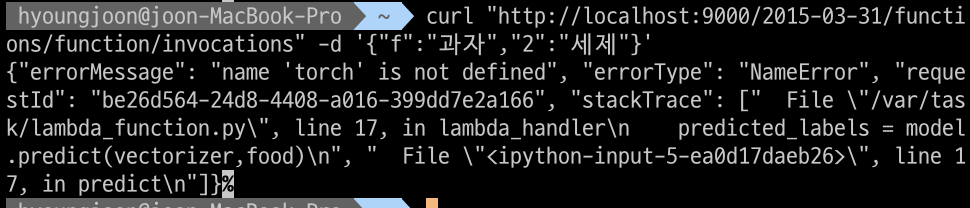
해결: 구현한 모델을 classifier.py에 Classifier 클래스에 있는 함수를 사용할 때 torch를 사용하는데 함수를 lambda_function.py에서 그냥 바로 구현했더니 성공했습니다.

문제상황 : 분명 테스트 컨테이너 만들고 테스트 했을때는 됐는데 ecr에 이미지를 올리고 lambda를 실행시켰더니 오류가 발생했습니다.
해결: 구성에서 lambda의 메모리와 소요시간을 늘렸더니 해결됐습니다.
'Dev' 카테고리의 다른 글
| fcm 이용해서 앱 푸쉬 구현 (0) | 2024.12.04 |
|---|---|
| 소켓 통신(채팅방 구현) (0) | 2024.12.04 |
| ElasticSearch로 검색 성능 높이기 (0) | 2024.12.04 |
| Swagger 사용하기 (1) | 2024.12.04 |
| Spring Security, JWT로 인증, 인가 구현하기 (0) | 2024.01.13 |