자주 조회되는 컬럼에 인덱스를 생성해두면 빠른 검색이 가능해지기 때문에 프로젝트에서 인덱스를 생성해서 성능을 높일 수 있는 부분이 있는지 찾아 보았습니다.
인덱스가 단점으로는 데이터 변경 시 인덱스도 업데이트 해야 되기 때문에 데이터를 추가하거나 변경, 삭제시에 느려지게 됩니다.
재료를 이용해 레시피를 검색하는 쿼리가 있어서 재료에 대해 인덱스를 생성해보았습니다.
jpa를 이용해 index를 생성했습니다.
@Table(
name = "recipe",
indexes = @Index(name = "idx_ingredient", columnList = "ingredient")
)
index를 생성하고 explain을 이용해서 인덱스가 잘 사용되는지 확인 했더니 인덱스가 사용되지 않고 있었습니다. (key가 null이기 때문에)
이유를 찾아보니 와일드카드(%)를 사용하면 B-Tree 인덱스를 사용할 수 없습니다.
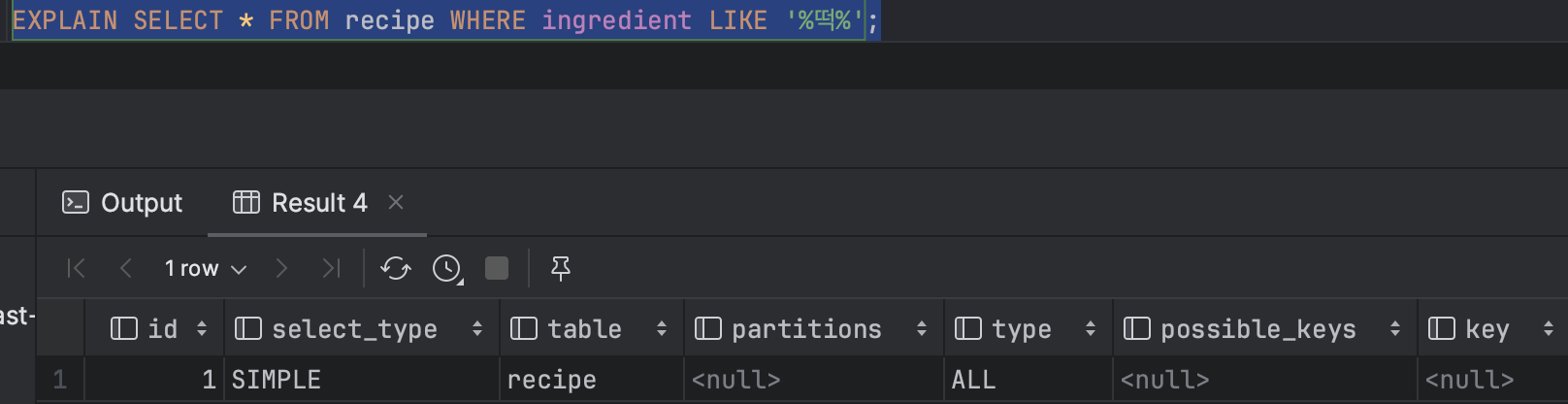
그래서 이 문제를 해결할 수 있는 Full-Text Search 인덱스를 사용했습니다.
인덱스 생성
ALTER TABLE recipe ADD FULLTEXT INDEX idx_ingredient_fulltext (ingredient);EXPLAIN
SELECT *
FROM recipe
WHERE MATCH(ingredient) AGAINST('떡*' IN BOOLEAN MODE)
ORDER BY recommend_count DESC;
key에 생성한 index가 들어가면 index를 사용하는 것입니다.
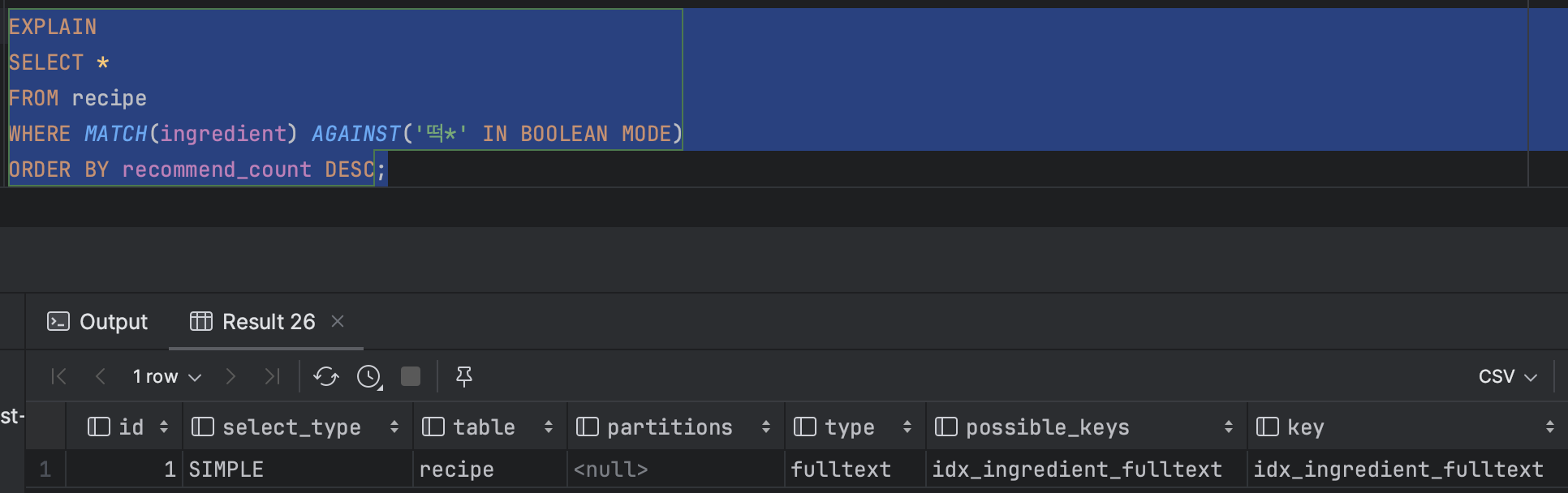
데이터도 정상적으로 조회되는 것을 확인할 수 있습니다.
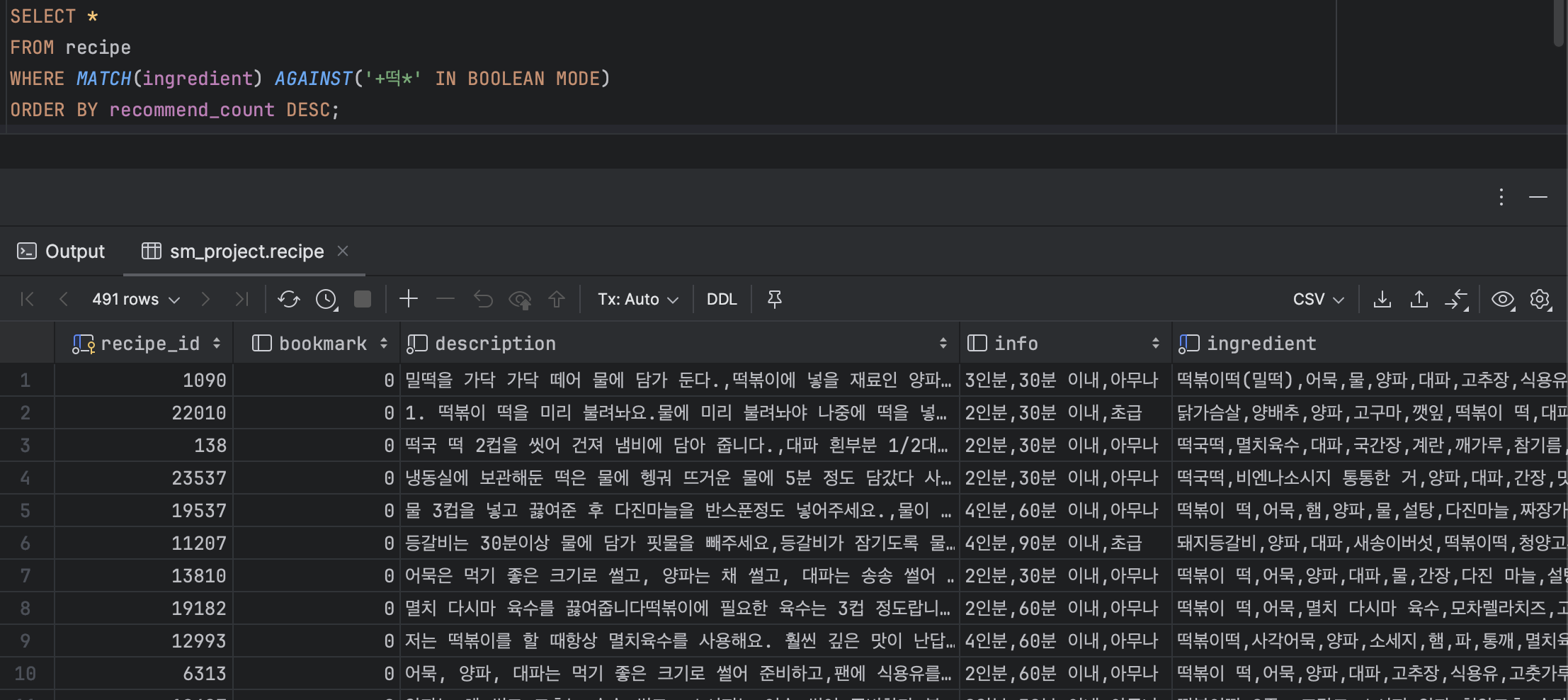
이제 스프링 api 서버에도 쿼리를 변경하겠습니다.
@Query(value = "SELECT * FROM recipe WHERE MATCH(ingredient) AGAINST(:ingredient IN BOOLEAN MODE) ORDER BY recommend_count DESC LIMIT :limit OFFSET :offset", nativeQuery = true)
List<Recipe> findByIngredientOrderByRecommendCountDesc(@Param("ingredient") String ingredient, @Param("limit") int limit, @Param("offset") int offset);
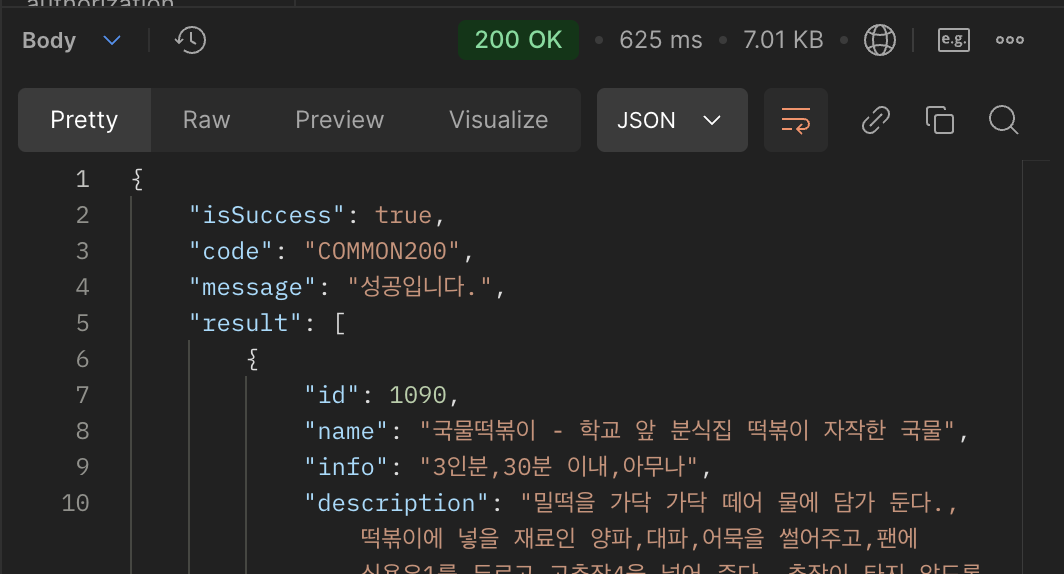
인덱스를 사용하지 않고 검색했을 때 응답 속도
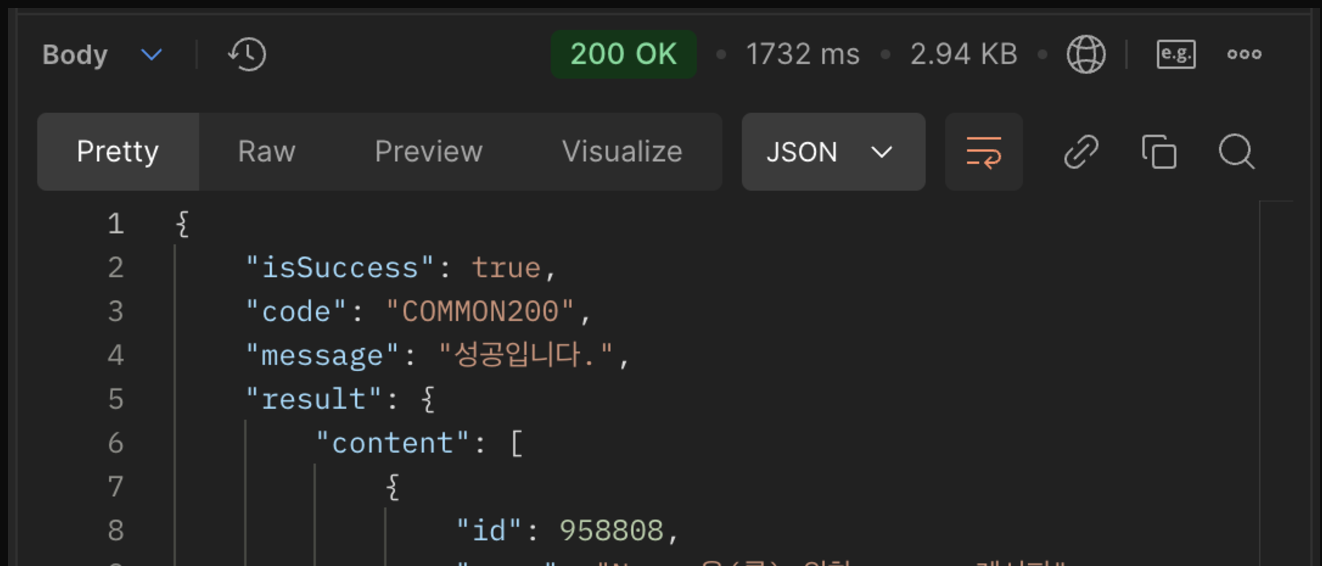
FTS 인덱스를 적용 했을 때 응답 속도
nativeQuery로 조회하는 것은 엔티티 매핑 오버헤드와 컨텍스트 관리 비용이 생기기 때문에 성능이 저하될 수 있습니다.
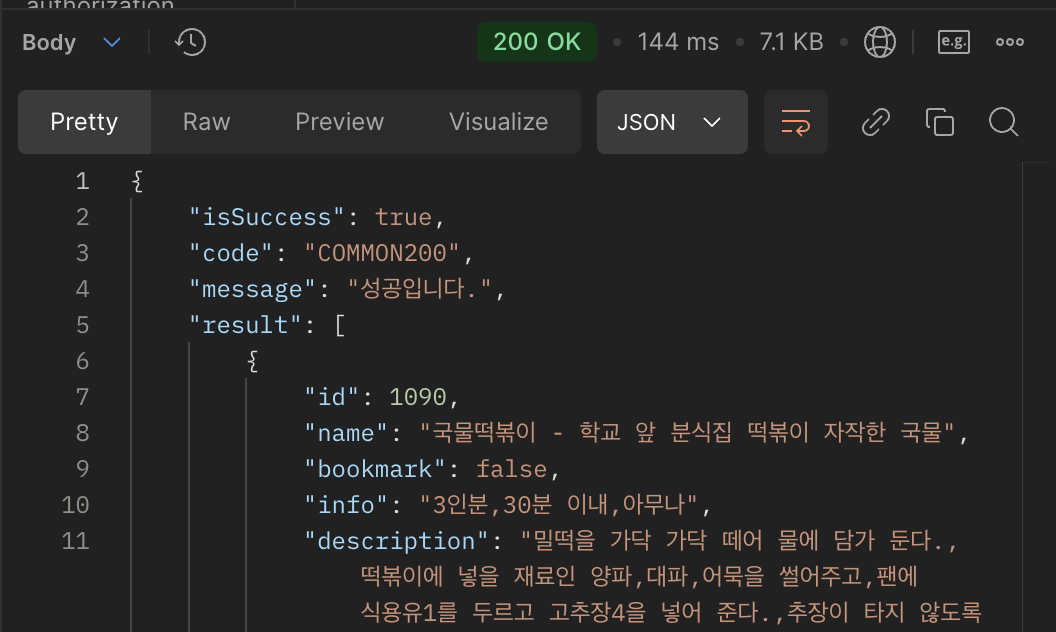
jdbc를 이용해서 검색했을 때 응답 속도
'Dev' 카테고리의 다른 글
| stream 만들어낸 이유가 있지 않을까? (0) | 2024.12.04 |
|---|---|
| N+1 문제 해결해서 성능 개선하기 (0) | 2024.12.04 |
| 일단 단위 테스트부터 테스트 코드 작성해보기 (0) | 2024.12.04 |
| 상품 주문하기 동시성 문제 해결하기 (0) | 2024.12.04 |
| 과도한 트래픽에 대한 방어하기 (1) | 2024.12.04 |